

2020年に、The NULL Value and its Purpose in Relational Database Systems(リレーショナルデータベースシステムにおけるNULL値とその目的)について学びました。その記事で述べたように、値NULLは、値が存在しないことを意味する特別なマーカーになりました。NULL値は、列が値を持つことができることを示している可能性がありますが、その値がどうあるべきかはまだわかりません。そのような状況では、テーブルフィールドに実際の値を入力するために必要なデータを最終的に収集するまで、それらはプレースホルダーとして機能します。
さらに、全ての主要なデータベースベンダーがデフォルト値としてNULLをサポートしていることを考えると、NULLを使用することだけが理にかなっていますね。どうしても必要な場合を除き、NULLの使用を避けるデータベース設計者がいます。彼らは私たちが知らない何かを知っているのでしょうか?続きを読んで見つけてください!
スペースに関する考慮事項
NULL値は「何もない」または「値がない」ことを表しますが、データベースでは値として扱われます。そのため、ハードドライブのスペースを占有します。そのため、NULL値を使用してハードドライブの容量を節約していると考えている場合は、間違っている可能性があります。実際、NULLは可変長値と見なされます。つまり、列の型に応じて、2・3バイトまたは数バイトになる可能性があります。値がフィールドに格納されるものよりも大きい場合、データベースは余分なバイトの余地を残します。その結果、データベースは、通常の値を使用した場合よりも多くのハードドライブスペースを占有する可能性があります。
情報が不足しているレコードを作成しないでください
一部のデータベース管理者は、レコードの全ての列を埋めることができない場合、レコードを作成すべきではないと主張しています。この議論は明らかに全てのユースケースに当てはまるわけではありませんが、その背後にある考え方は、全てのフィールドにプレースホルダー無しで実際の値がある場合にのみレコードを作成する必要があるということです。例えば、銀行のアプリケーションでは、トランザクションの金額がわからない場合、トランザクションを続行しません。当然のことですが、この種の厳格な基準は、ユーザーデータを収集するeコマースやWebサイトなどの他の業界ではうまく機能しません。
複雑なSQL
もう1つのデメリットは、データベースのストアドプロシージャに影響します。ほとんどのデータベースはNULL値を検出する機能を提供していますが、NULLを他の値と区別するために特別な注意を払う必要があります。これは、SQLプロシージャーが必要以上に長くなる可能性があることを意味し、同様に読み取りが複雑になる可能性があります。データベース管理者は、手順が複雑すぎる、または理解できない場合、コードの変更を拒否することがあります。
適切な例として、値、空の文字列、およびNULLの組み合わせを含むNavicat Premium 16の小さなテーブルを次に示します。
Navicatでは、編集メニューから空の文字列またはNULLを簡単に挿入できます。
次に、様々な基準に基づいて名前の数をカウントするクエリを示します。
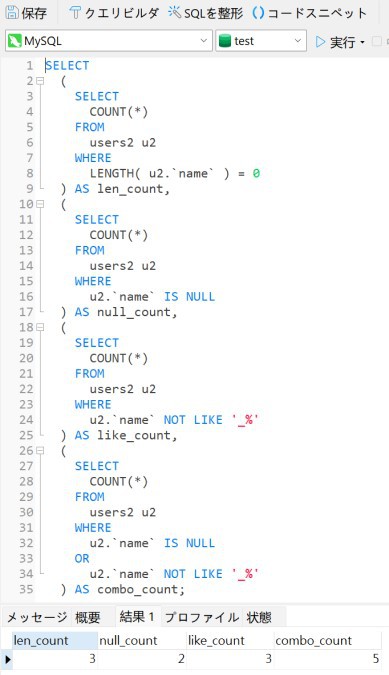
レコード 4、5、7、8、および10には値がないため、カウント5を探していました。ただし、combo_countだけが5を返しました。これは、NULL値には長さがないため、length()関数によってNULLが取得されないためです。
この例から、NULL値を許可すると、探している種類のデータを取得するのに非常に苦労する可能性があると結論付けることができます。さらに、NULL値を許可すると、値が存在するかどうかを完全に確認できないため、データベース内のデータに関する信頼性が低下する可能性があります。
結論
ほとんどのデータベース担当者は、データベーステーブルにいくつかのNULL値を許可することを選択します。これは、よく知られているほぼ全てのデータベースのデフォルト値であり、欠損データのプレースホルダーとして適切に機能するためです。一方で、一部のDBAは、NULLはそれに伴う余分な問題に見合う価値がないと感じていることもわかりました。この話の教訓は、データベースを設計する前に独自のビジネスプロセスを検討し、データに最適な構造を選択する必要があるということです。




