

SQL の EXISTS 演算子は、他のデータの存在(または非存在)に基づいてデータを検索する簡単な方法を提供します。より具体的には、サブクエリの結果を評価し、行が返されたかどうかを示すブール値を返す論理演算子です。IN演算子もほぼ同じ目的で使用できますが、いくつかの違いがあります。本日のブログでは、いくつかの例を使用して EXISTS 演算子を使用する方法を説明し、EXISTS 演算子ではなく IN 演算子を使用するタイミングについてガイダンスを提供します。
EXISTS の動作
EXISTS 演算子は SELECT、UPDATE、INSERT、または DELETE 文で使用できますが、ここではシンプルにするために SELECT クエリに限定します。そのため、使用する構文は次のようなものになります。
SELECT column_name(s)
FROM table_name
WHERE EXISTS ( SELECT column_name(s)
FROM table_name
WHERE condition );
これらのクエリは、銀行のデータベースなどで見られるような、customer と account という2つのPostgreSQL テーブルに対して実行されます。以下は、Navicat for PostgreSQL のグリッドビューでの表示です。
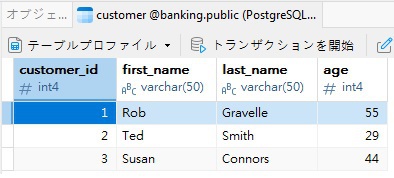
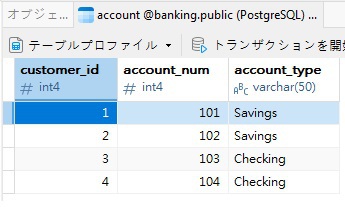
これで、以下のクエリを使用して、customer_id に関連付けられたアカウントを持つすべての顧客を見ることができます。
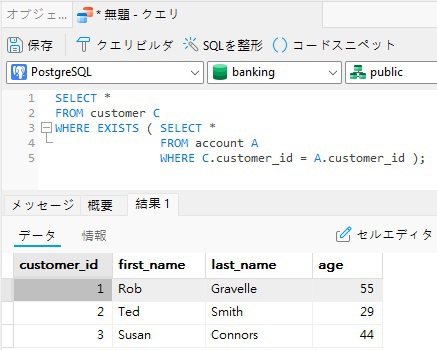
SELECT *
FROM customer C
WHERE EXISTS ( SELECT *
FROM account A
WHERE C.customer_id = A.customer_id );
以下は、Navicat Premium のクエリエディタでの上記のクエリと結果です。
EXISTSにNOTを付けて使用する
逆に、EXISTS 演算子の前に NOT キーワードを付けることで、サブクエリに一致する行がない場合にのみレコードを選択するクエリになります。NOT EXISTS を使用して、すべての孤立アカウント、つまり、関連付けられた顧客のないアカウントを取得できます。
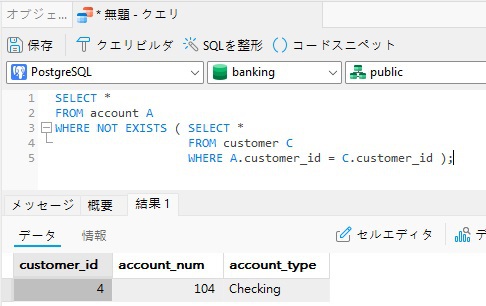
SELECT *
FROM account A
WHERE NOT EXISTS ( SELECT *
FROM customer C
WHERE A.customer_id = C.customer_id );
これは、customer テーブルにそのIDを持つ顧客が存在しないため、顧客#4のアカウントを返します。
EXISTS を JOIN で置き換える
EXISTS 演算子を使用するクエリは、サブクエリが外部クエリの各行に対して実行される必要があるため、実行速度が少し遅くなることがあります。そのため、可能であれば JOIN を使用することを検討してください。実際、上記の EXISTS クエリは LEFT JOIN を使用して書き直すことができます。
SELECT C.* FROM customer C LEFT JOIN account A ON C.customer_id = A.customer_id;
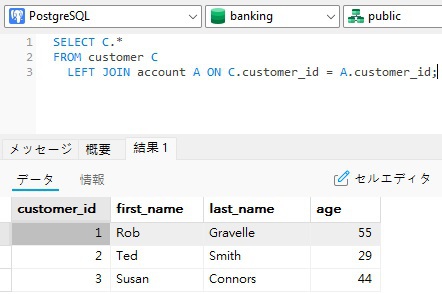
IN 演算子と EXISTS 演算子
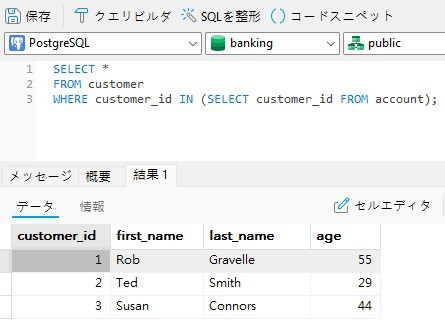
IN演算子は通常、列を特定の値のリストでフィルタリングするために使用されますが、サブクエリの結果にも適用できます。以下は、最初のクエリと同等ですが、今回は EXISTS ではなく IN を使用しています。
SELECT * FROM customer WHERE customer_id IN (SELECT customer_id FROM account);
SELECT * とは異なり、比較したい列のみを選択できることに注意してください。それでも、IN クエリは同じ結果を生成します。
両演算子は非常に似ているため、データベース開発者はしばしばどちらを使用すべきか迷ってしまいます。一般に、特定の値のリストに基づいて行をフィルタリングしたい場合は、IN 演算子を使用すべきです。サブクエリで特定の条件を満たす行が存在するかどうかのチェックが必要な場合は、EXISTS を使用してください。
まとめ
本日のブログでは、EXISTS 演算子の使い方と、EXISTS または IN を使用するかどうかを決定する方法について学びました。
Navicat Premium 17 を使ってみたいですか? Windows、macOS、および Linux オペレーティングシステムで、すべての機能が14日間完全に試用できる無償トライアル版をダウンロードできます。




