

異種リポジトリ間(つまり、ソースデータベースとターゲットデータベースが異なるプロバイダーの異なるデータベース管理システムである場合)でデータを移行するには、いくつかの課題があります。場合によっては、両方のデータベースに同時に接続できます。しかし、それが不可能な場合もあります。このようなジレンマに直面した場合、データベースの実務者はダンプファイルからテーブルにデータを入力するしかありません。Navicat は、そのプロセスにおいて大きな助けとなります。インポートウィザードを使用すると、CSV、TXT、XML、DBF など、さまざまなソースからテーブル/コレクションにデータをインポートできます。さらに、設定をプロファイルとして保存して、将来使用したり、タスクの自動化を設定したりできます。今日のブログでは、Navicat インポートウィザードを使用して、無料の Navicat Premium Lite 17 を使用して、PostgreSQL "dvdrental" databaseから MySQL 8 インスタンスにデータを移行します。
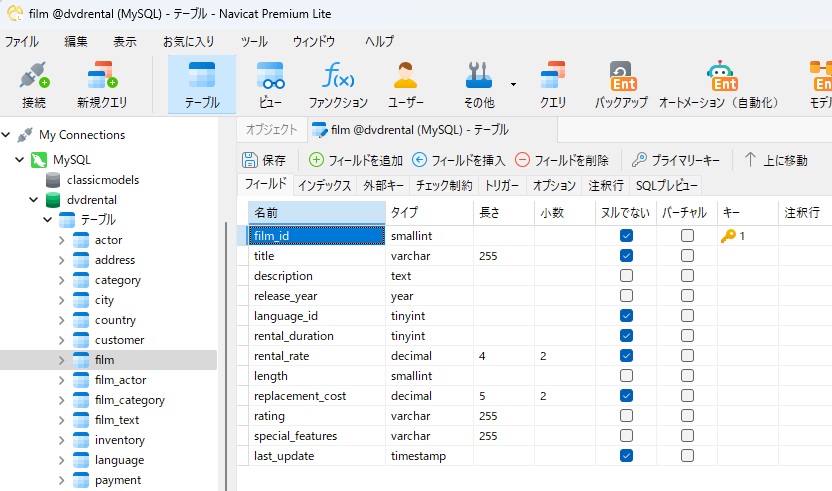
このチュートリアルでは、PostgreSQL の DAT ファイルを使用して、MySQL 8 の film テーブルにデータを入力します。テーブルデザイナでのテーブル定義を次に示します。
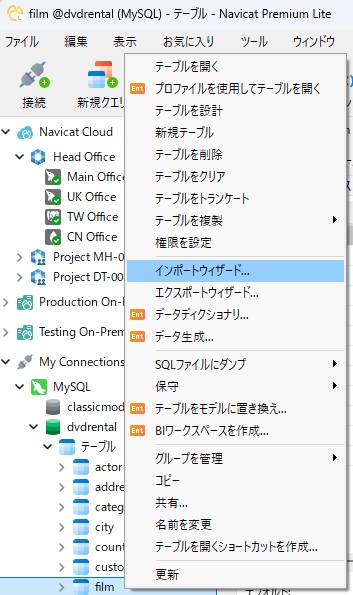
インポートウィザードを起動するには、Navicat ナビゲーションペインでターゲットテーブルを右クリック(macOS では Ctrl キーを押しながらクリック)し、コンテキストメニューから「インポートウィザード.」を選択します。
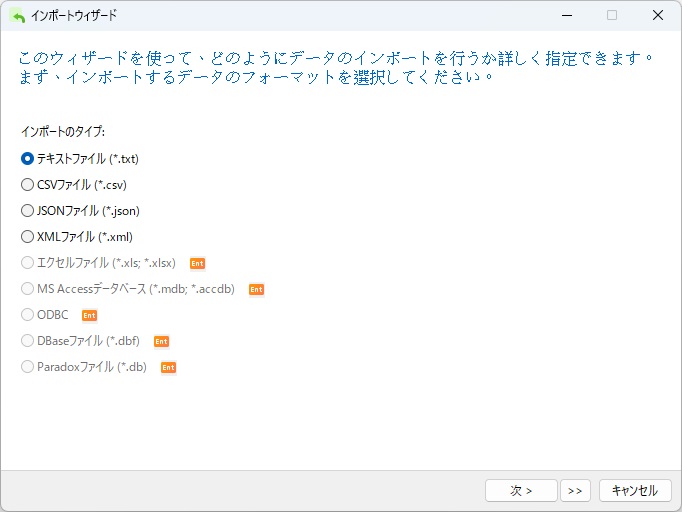
ウィザードの最初の画面では、ソースファイルを選択します。Lite エディションでは、TXT、CSV、XML、JSON などのテキストベースのファイルのみがサポートされていることに注意してください。 ここでは .dat ファイルを使用していますが、.txt、.csv、.dat 形式を包含するテキストファイルオプションを選択できます。
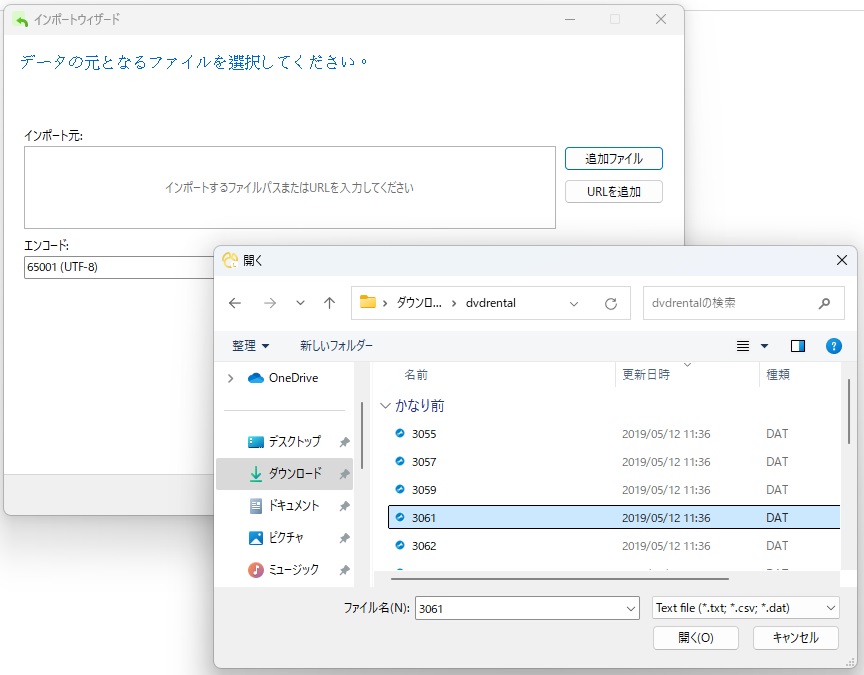
次の画面では、DATファイルを選択します。各テーブルに1つのファイルがあります。filmテーブルのファイルは「3061.dat」という名前です。
次に、区切り文字を設定します。レコードは改行文字(LF)を使用して区切られ、列はタブ文字を使用して区切られます。テキスト値を囲む引用符はないため、「テキスト修飾子」テキストボックスから二重引用符(")を必ず削除してください。

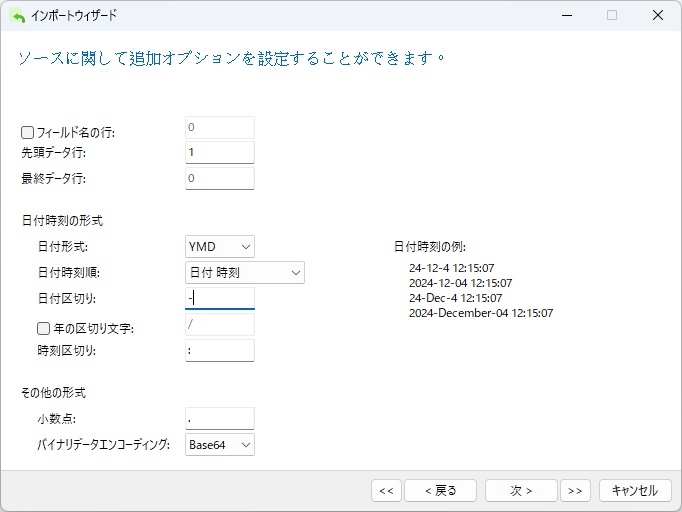
次の画面には、いくつかの追加オプションがあります。ここでは、DATファイルにはフィールド名が含まれていないため、「フィールド名行」チェックボックスをオフにする必要があります。また、インポートする日付がYYYY-MM-DD hh:mm:ss.ms形式(例:2013-05-26 14:50:58.951)であるため、日付順序を年/月/日(「YMD」)に変更し、スラッシュ(/)区切り文字をダッシュ(-)に置き換える必要があります。
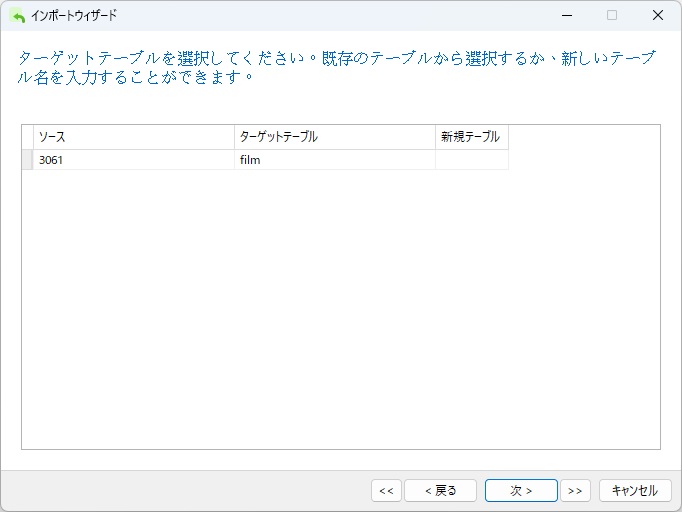
既存のテーブルを選択するか、新しいテーブルを作成するかを選択できます。インポートウィザードの起動時にターゲットテーブルを選択したので、ここに表示されているはずです。
次のステップは、ソースフィールドをデスティネーションテーブルのフィールドにマッピングすることです。ここでは、フィールドが順番に並んでいると想定してはいけません。DATファイルのエントリをざっと見ると、last_update列とspecial_features列が逆になっていることがわかります。
5 African Egg A Fast-Paced Documentary of a Pastry Chef And a Dentist who must Pursue a Forensic Psychologist in The Gulf of Mexico 2006 1 6 2.99 130 22.99 G 2013-05-26 14:50:58.951 {"Deleted Scenes"} 'african':1 'chef':11 'dentist':14 'documentari':7 'egg':2 'fast':5 'fast-pac':4 'forens':19 'gulf':23 'mexico':25 'must':16 'pace':6 'pastri':10 'psychologist':20 'pursu':17
ダイアログ内の任意の場所を右クリック(macOSではCtrlキーを押しながらクリック)し、コンテキストメニューから「すべて直接一致」を選択すると、フィールドをターゲットテーブルのフィールドにすばやくマッピングできます。ただし、それが完了したら、ターゲットフィールドのドロップダウンからlast_update列とspecial_features列を手動で選択して、順序を変更する必要があります。
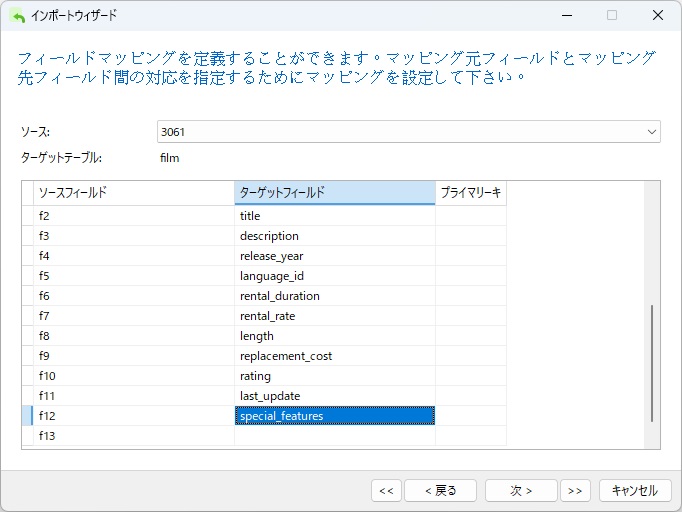
フィールド13(f13)は無視しても問題ありません。
インポートモードでは、テーブルが空であるはずなので、レコードを「追加」または「コピー」のいずれかを選択できます。
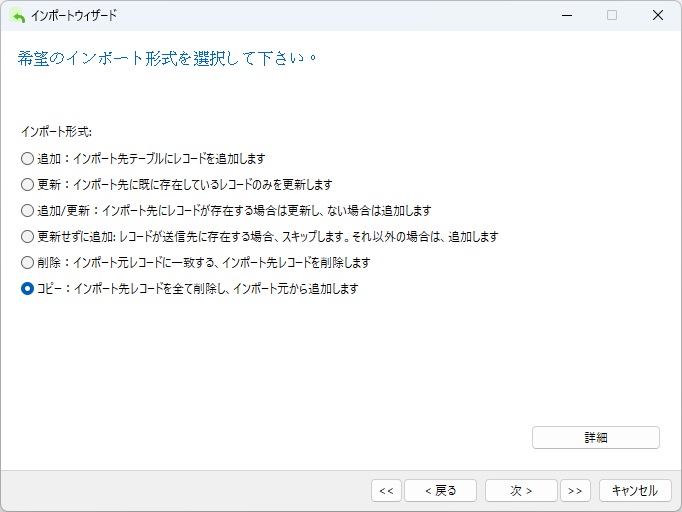
あるデータベースの種類から別の種類に移行する場合、データ変換エラーが発生する可能性が高くなります。そのため、詳細設定の「拡張挿入ステートメントを使用」チェックボックスをオフにすることをお勧めします。これにより、Navicatは、次のような構文を使用して複数の行を結合するのではなく、各レコードに対して個別のINSERTステートメントを発行します。
INSERT INTO `film` VALUES (1, 'African Egg', 'A Fast-Paced...'), (2, 'Rumble Royale', 'A historical drama...'), (3, 'Catherine the Great', 'A new take on...'), etc...
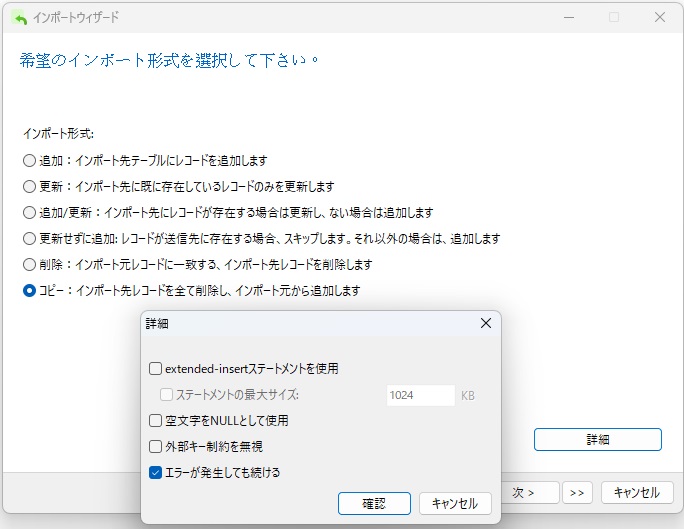
さあ、いよいよ「開始」ボタンをクリックしてインポートプロセスを開始しましょう。
予想通り、いくつかのエラー(正確には3つ)が発生しましたが、1003行のうち1000行がターゲットテーブルに追加されました。
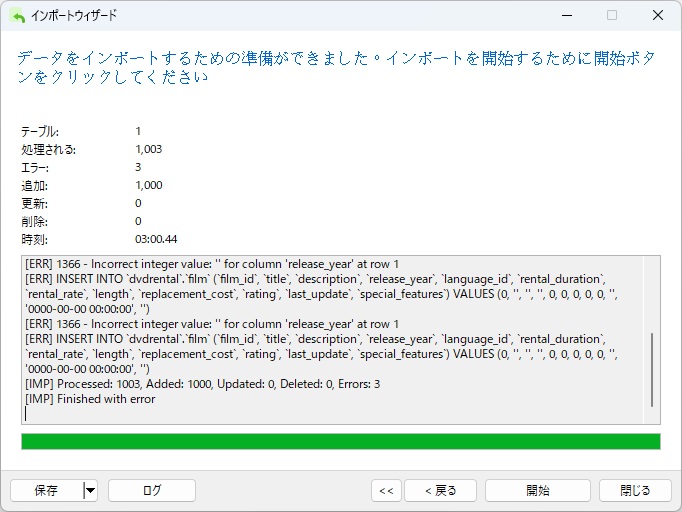
まとめ
Navicatのインポートウィザードを使用すると、異種リポジトリ間でのデータ移行に費やす時間を大幅に短縮できます。CSV、TXT、XML、DBF、ODBCデータソースなど、幅広い入力をサポートしています。
Windows、macOS、Linuxオペレーティングシステムで利用できるNavicat Premium Lite 17 を試してみたいですか?ここから無料でダウンロードできます。




