

ファーストネームを格納するテーブル列など、テーブル列には重複した値が多数含まれる場合があります。様々な(個別の)値をリストすることに興味がある場合は、複雑なSQLステートメントを用いらずにリストする方法が必要です。PostgreSQL、SQL Server、MySQLなどのANSI SQL準拠のデータベースでは、列から個別の値のみを選択する方法は、SQL DISTINCT句を使用することです。SELECTステートメントの結果セットから重複を削除し、一意の値のみを残します。このブログ記事では、その使用方法を学びます。
構文と動作
SQL DISTINCT句を使用するためには、次のようにSELECTと列および/または式リストの間にDISTINCTキーワードを挿入するだけです:
SELECT DISTINCT columns/expressions FROM tables [WHERE conditions];
クエリでは、SELECTリスト内の指定された全ての列の値の組み合わせを使用してその一意性を評価するため、ステートメントに1つ以上の列や式を含めることができます。また、NULL値を持つ列にDISTINCT句を適用する場合、DISTINCT句はNULLを1つだけ保持し、残りは削除します。つまり、DISTINCT句は全てのNULL値を同じ値として扱います。
1列の例
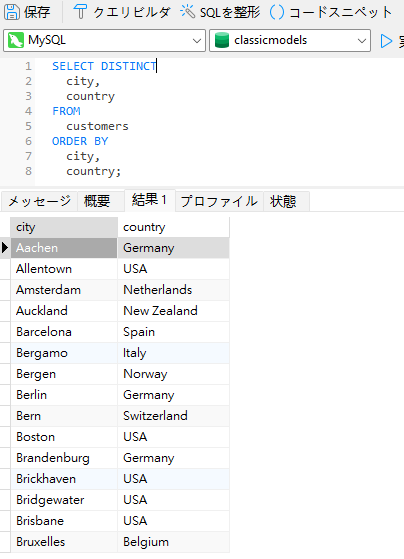
クエリの一般的な使用例は、組織の顧客またはユーザーの全ての都市や国をリストすることです。以下は、classicmodelsサンプルデータベース に対する Navicat Premium 16のクエリです:
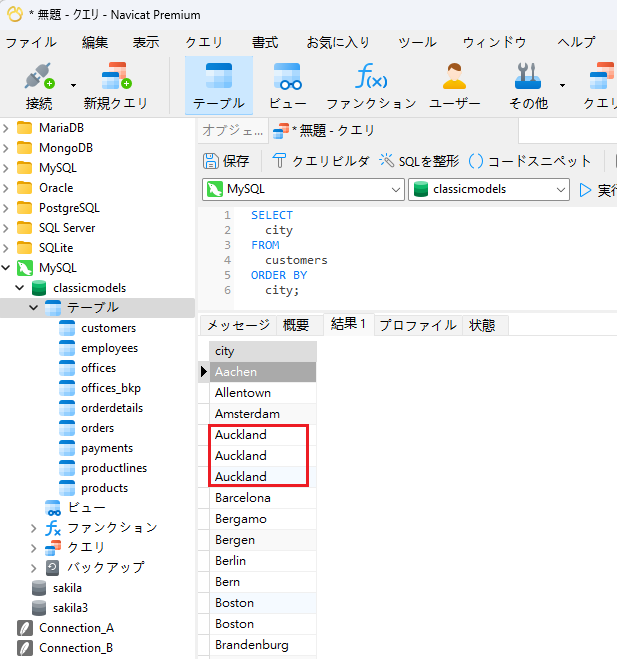
赤い枠線で強調表示されているように、重複した都市があります。
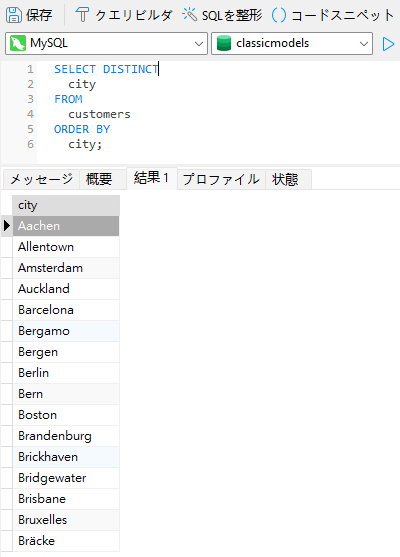
一意の都市のリストを取得するためには、SELECTステートメントにDISTINCTキーワードを追加します:
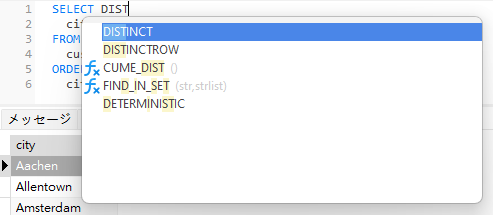
Navicatのコード補完機能を利用して、DISTINCTキーワードを表示できます。Navicatは、エディタにSQLステートメントを入力するとドロップダウンリストに情報を表示します。これは、ステートメントの補完やデータベースオブジェクト(データベース、テーブル、フィールド、ビューなど)の使用可能なプロパティを適切なアイコン付きで表示して支援します:
複数列の例
DISTINCTキーワードは複数の列に適用することもできます。そのコンテキストでは、クエリは、選択された全ての列が一意である行のみを返します。まず、最後のクエリにcountryフィールドを追加しましょう:
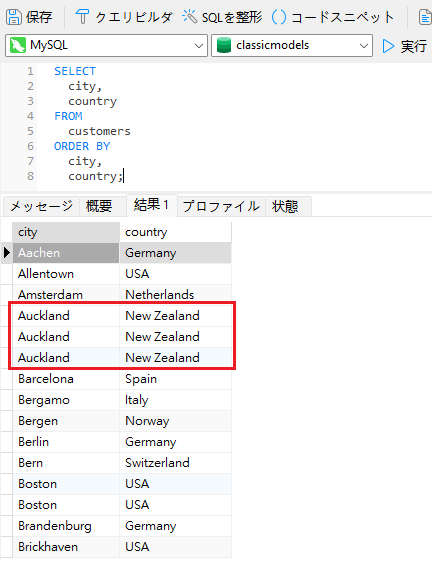
またまた重複が見られますが、重複した都市は同じ国に存在する可能性が高いため、これは当然のことです。
もう一度、DISTINCTキーワードを追加すると、クエリエンジンは都市と国の両方の列の値の組み合わせを調べて、重複を評価して削除します:
NULL値を含むDISTINCT
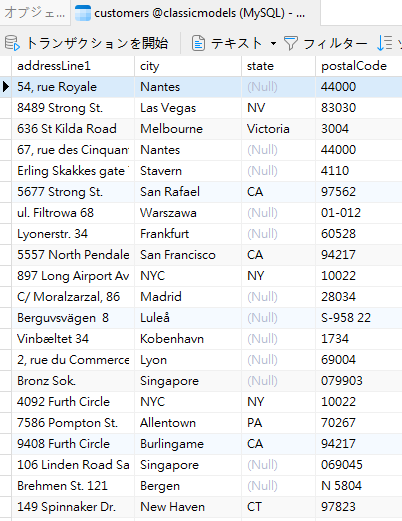
前述したように、DISTINCT句は全てのNULL値を同じ値として扱うため、結果セットにはNULLのインスタンスが1つだけ含まれます。以前にクエリを実行したのと同じcustomersテーブル内のそのような列をクエリすることで、自分自身でテストできます:
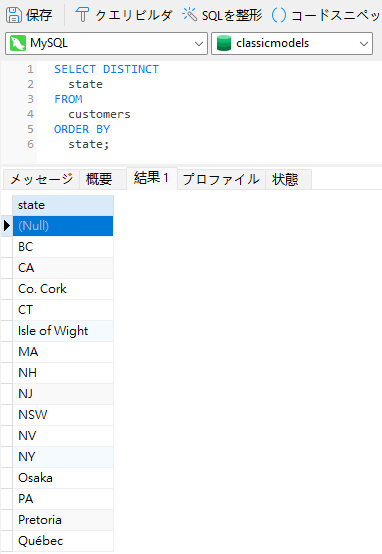
予想どおり、DISTINCTキーワードを追加すると、1つを除く全てのNULLのインスタンスが削除されました:
リレーショナルデータベースからの個別の値の選択に関する最終的な考え方
このブログ記事では、SELECTステートメントの結果セットから重複を削除し、一意の値のみを残すSQL DISTINCT句の使用方法を学びました。これまで見てきたように、NULL値だけでなく1つ以上の列でも機能します。ただし、1つ以上の列に集計関数を適用する必要がある場合は、代わりにGROUP BY句を使用する必要があります。




