

Arrays and Enums
PostgreSQLは、拡張性と多用途性で知られており、従来の整数や文字列を超えたいくつかのデータ型を提供します。これらには、開発者に高度なデータモデリング機能を提供する配列と列挙型が含まれます。このブログ記事では、これらの洗練されたデータ型を詳しく掘り下げ、その使用法と利点を無料の dvdrentalサンプルデータベース のコンテキスト内で示します。
配列型
PostgreSQLの配列を使用すると、単一のデータベースフィールド内に複数の値を格納できます。この機能は、データのリストまたはセットの処理が不可欠なシナリオでは非常に貴重であることがわかります。実際の例を考えてみましょう。各映画に出演した俳優と一緒に映画を保存したいとします。配列データ型を利用すると、これを効率的に実現できます。まず、新しい"films_with_actors"テーブルを作成してデータを取り込むためのステートメントを次に示します:
CREATE TABLE films_with_actors (
film_id SERIAL PRIMARY KEY,
title VARCHAR(255),
actors TEXT[]
);
INSERT INTO films_with_actors (title, actors) VALUES
('Inception', ARRAY['Leonardo DiCaprio', 'Joseph Gordon-Levitt']),
('The Shawshank Redemption', ARRAY['Tim Robbins', 'Morgan Freeman']);
Navicatでは、テーブルデザイナーを使用してテーブルを作成できます:
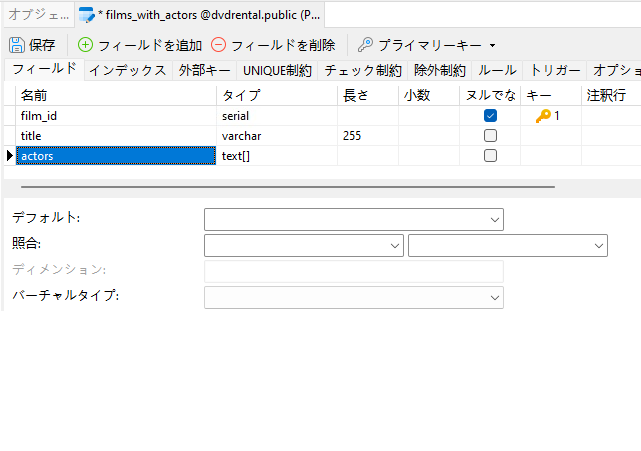
注意してほしいことは、テキスト型に角括弧"[]"を追加すると、Navicatはそれを配列型として認識し、テーブルの保存時にディメンションフィールドに"1"を追加して、それが1次元配列であることを示すことです。
テーブルを作成したら、テーブルにデータを追加できるようになります。各配列内にどの値を含めるかをNavicatに伝えるために、必ず配列値を中括弧"{}"で囲んでください:

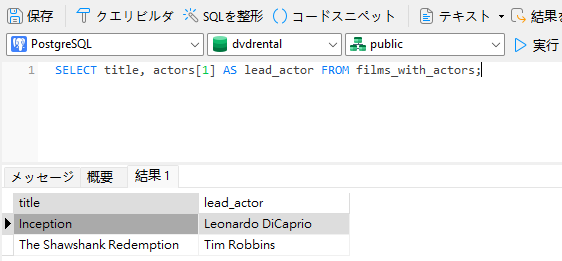
クエリでは、角括弧内に目的のインデックスを追加することによって、特定の配列要素を参照できます。したがって、"actors[1]"は最初の配列値をフェッチします:
列挙型
"Enumerated"の略称であるEnum型(列挙型)を使用すると、開発者は列に可能な値の固定セットを定義できます。これにより、データベーススキーマ内のデータの整合性と明確さが強化されます。"films_with_actors"テーブルに"rating"列を追加することで、これを説明してみましょう。次のDDLステートメントを使用して、映画評価の列挙型を定義できます:
CREATE TYPE rating AS ENUM ('G', 'PG', 'PG-13', 'R', 'NC-17');
ALTER TABLE films_with_actors ADD COLUMN rating rating;
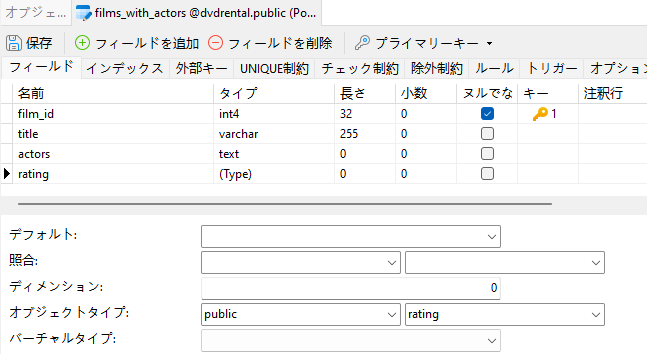
Navicatでは、列リストの上にある"フィールドを追加"ボタンをクリックして、テーブルデザイナーに新しい列を追加できます。上記のCREATE TYPEステートメントを使用してrating列挙型を作成した後、タイプドロップダウンから”(タイプ)”項目を選択し、次にオブジェクトタイプリストからrating項目を選択することで、rating列挙型を選択できます:
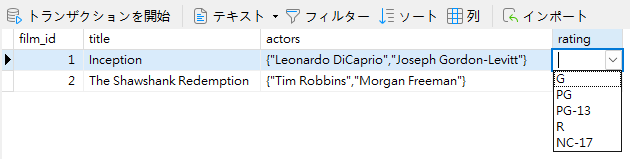
テーブルのrating列には、定義した列挙値を含むドロップダウンが含まれるようになります:
結論
PostgreSQLの配列データ型と列挙データ型は、複雑なデータ構造を効率的にモデル化するための強力なツールを開発者に提供します。これらの高度な機能を活用することにより、開発者はデータの整合性を強化し、クエリを合理化し、より堅牢なデータベーススキーマを構築できます。来週のブログでは、PostgreSQLの高度なデータ型の探索を、範囲型を見て、締めくくります。範囲型は、単一のデータベースフィールド内の値の範囲を表す簡潔な方法を提供するため、時間データから数値間隔に至るまで、様々な定義域で非常に役立ちます。
PostgreSQLデータベース開発用の使いやすいグラフィカルツールをお探しですか?Navicat 16 For PostgreSQLは全てをカバーします。こちら をクリックして、全ての機能が使用可能なアプリケーションをダウンロードし、14日間無料でお試しください。